wheatgreaser
making an autograd engine
so what i want to make is an autograd engine. im following the messiah, ofc.
check out the final result here
5th Aug, 2024:
an autograd engine implements backpropogation. you can imagine the loss function as a function that takes in a lot (say, n) of weights as input, and gives “loss” as an output. now we want to tweak the weights such that the loss is minimal (gradient descent). now, we do this weight tweaking using backprop. now, let’s look at how each individual node is designed, each middle layer node basically has a set of inputs that is multiplied by a weight (think of weight as the importance of that particular input) then if the sum of all the values is above a certain threshold, this node emits an output.
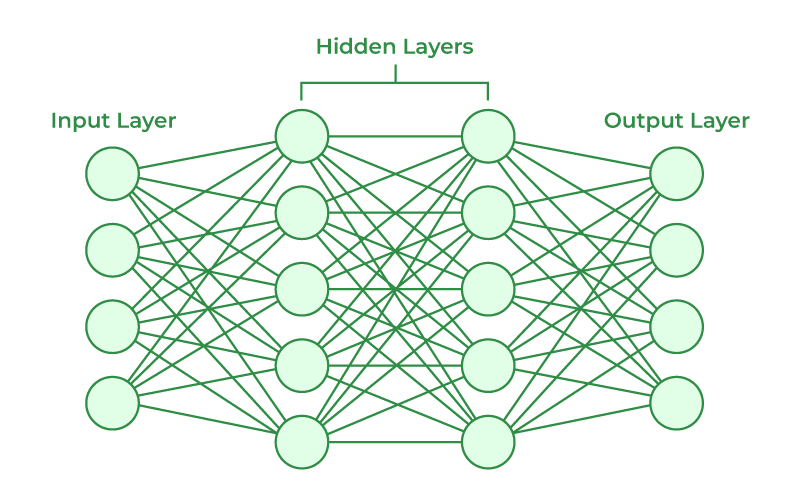
now what we want to do is iteratively tune the weights to minimize the loss.
the autograd engine im building allows you to build an expression graph. like:
a = 3
b = 4
c = a + b
d = a * b
e = c ** d
and after that using the chain rule from calculus we can find de/da and de/de , i.e, how the value of the input affects the output.
neural networks are nothing but mathematical expressions and so we’re going to be dealing with expression graphs like this (but simpler). it should be apparent by now that the concept of backprop is independent of neural networks, we’re just iteratively modifying the weights to minimize a function.
you might have notcied that we deal with scalars, not tensors (like my competitor tensorflow, im coming for your throat google). the concept is the same, these scalars are packaged into tensors (arrays) so that we take advantage of the parallelism. BUT REMEMBER, THE MATH AND THE CONCEPTS ARE THE SAME.
working with python after working with a strictly typed language like java or c++ is such a pain. working with OOP in c++ and java is waaaaaaaaaaaaaay better. like wtf is self, wtf is init, why cant you have regular ass contructors (just let me type the class name without a return type)??
python gives me bowel irritability. look at this shit. why dont they have an array and be done with it like civilized human beings.
right now, this the function i’ve (ok not me specifically but fuck off)
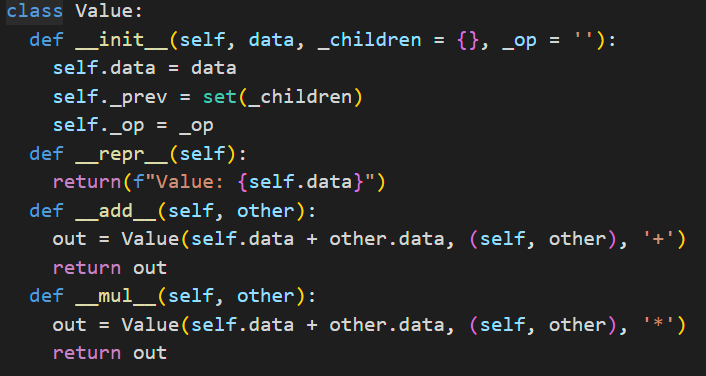
basically you have a constructor that assigns values to the instance variables we have the “data” which holds, never would have guessed in a million years, the data. then we have _children which holds all the children variables, for example, if i make an expression graph like c = a + b, a and b are the children of c, i have also have the _op instance variable which holds the operation. for those of you new to python the underscore functions like add and mul are called when i use the respective operator.
we basically now have the functionality to build out expression graphs, we can now do the backprop. we need to find the derivative of the final output with respect to each individual variable in the expression graph.
example:
a = 10
b = 5
c = 7
g = 10
d = a + b
e = c * g
f = d + e
here f is the final output, now we need to find the derivative of f with respect to e, d, c, b, a and g. we can do this easily, df/df = 1, df/de and df/dd are just 1, and by using chain rule df/dc = df/de * de/dc. simple as that. since we now know the graidents we know how the output will respond to a nudge to a particular data. if df/da > 0 then if a += 0.1, f will also go up by a bit.
when we deal with an actual neural network we use weights, not the data itself, the data is fixed, lets say i have a handwritten number classifier neural net, the input pixel values are constant, we do not touch them instead we modify the weights (and therefore their contribution to the output). the weights are basically multiplied to the data and then this value is passed as an input to the next node.
in an actualy neuron we use an activation function to squash the output between -1 and 1. andrej is using tanh so im using tanh. we need a non linear activation function so that we can draw non linear boundaries between outputs, we introduce many layers in our network for extracting features at different levels. if we use a linear activation function its like having a single layer.
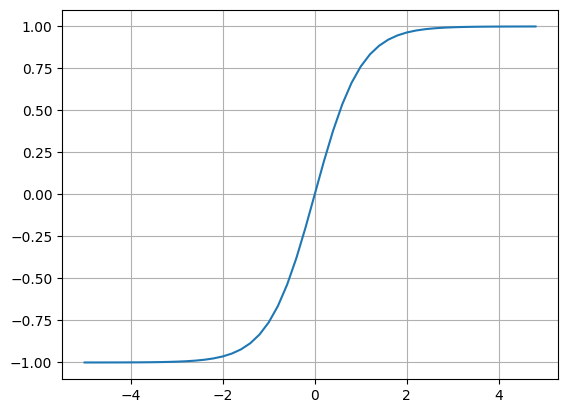
activation functions in the output layer can also help express the output of the network as a probability distribution or a binary classification.
6th Aug, 2024:
now i need to implement the chain rule programitcally. its, suoper simple, we basically set the gradient (final output with respect to the current variable) as the gradient of the local output (final output with respect to local output) times the the derivative of the local output with respect to x. if we iteratively do this for each node we basically get the gradient of the final output with respect to each individual node.
we use topological sort to traverse backwards through the expression graph. it works such that the current variable is only going to be in the list if all its children are in the list.
badabing badaboom, autgorad done. LETS FUCKING GOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO.